All Optional Arguments¶
Three main configuration classes are specific in zamba:
VideoLoaderConfig: Defines all possible parameters for how videos are loadedPredictConfig: Defines all possible parameters for model inferenceTrainConfig: Defines all possible parameters for model training
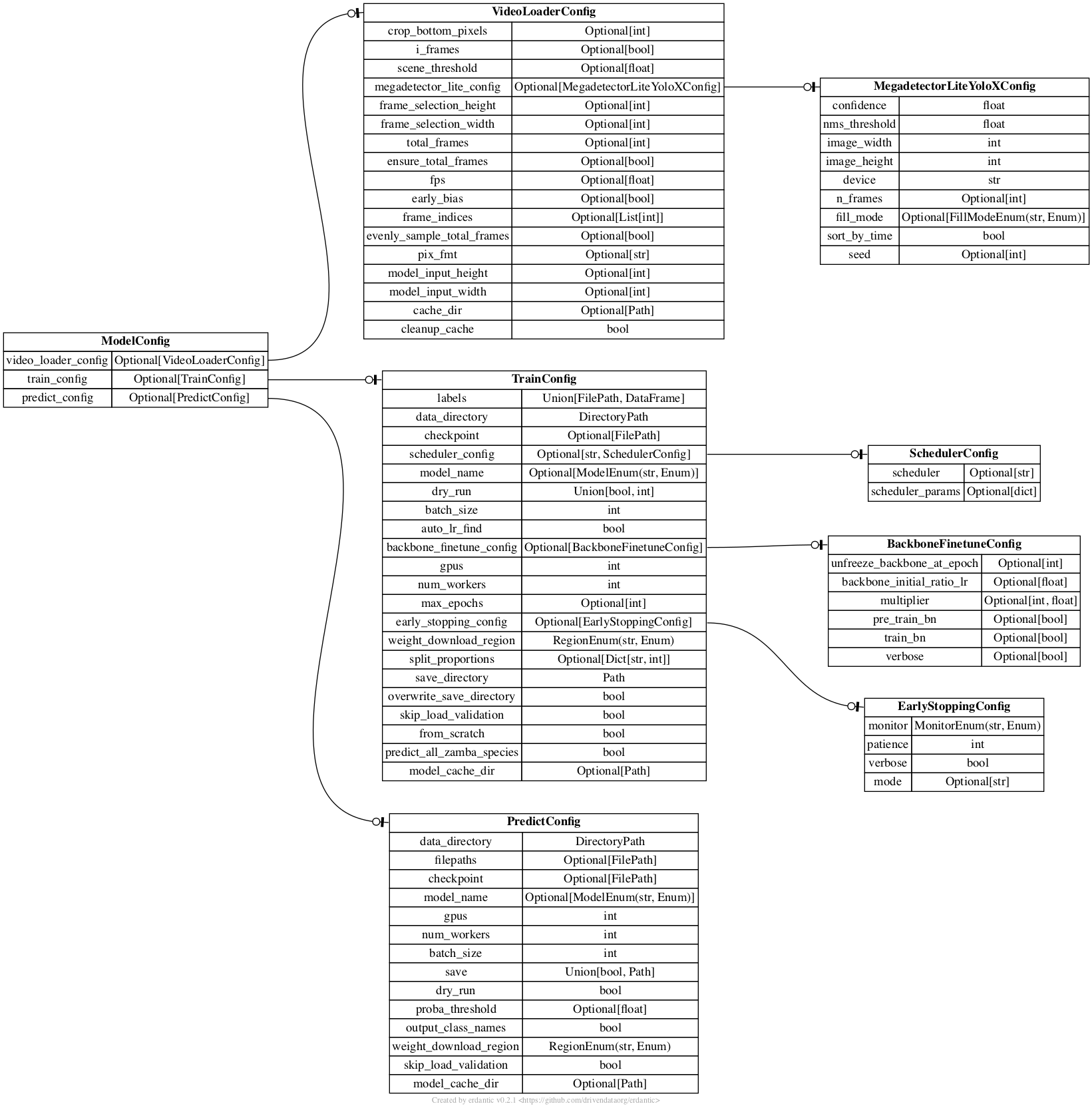
Here's a helpful diagram which shows how everything is related.
Video loading arguments¶
The VideoLoaderConfig class defines all of the optional parameters that can be specified for how videos are loaded before either inference or training. This includes selecting which frames to use from each video.
All video loading arguments can be specified either in a YAML file or when instantiating the VideoLoaderConfig class in Python. Some can also be specified directly in the command line.
video_loader_config:
model_input_height: 240
model_input_width: 426
total_frames: 16
# ... other parameters
from zamba.models.model_manager import predict_model
from zamba.models.config import PredictConfig
from zamba.data.video import VideoLoaderConfig
predict_config = PredictConfig(data_directory="example_vids/")
video_loader_config = VideoLoaderConfig(
model_input_height=240,
model_input_width=426,
total_frames=16
# ... other parameters
)
predict_model(
predict_config=predict_config, video_loader_config=video_loader_config
)
Let's look at the class documentation in Python.
>> from zamba.data.video import VideoLoaderConfig
>> help(VideoLoaderConfig)
class VideoLoaderConfig(pydantic.main.BaseModel)
| VideoLoaderConfig(*,
crop_bottom_pixels: int = None,
i_frames: bool = False,
scene_threshold: float = None,
megadetector_lite_config: zamba.models.megadetector_lite_yolox.MegadetectorLiteYoloXConfig = None,
frame_selection_height: int = None,
frame_selection_width: int = None,
total_frames: int = None,
ensure_total_frames: bool = True,
fps: float = None,
early_bias: bool = False,
frame_indices: List[int] = None,
evenly_sample_total_frames: bool = False,
pix_fmt: str = 'rgb24',
model_input_height: int = None,
model_input_width: int = None,
cache_dir: pathlib.Path = None,
cleanup_cache: bool = False) -> None
...
crop_bottom_pixels (int, optional)¶
Number of pixels to crop from the bottom of the video (prior to resizing to frame_selection_height). Defaults to None
i_frames (bool, optional)¶
Only load the I-Frames. Defaults to False
scene_threshold (float, optional)¶
Only load frames that correspond to scene changes. Defaults to None
megadetector_lite_config (MegadetectorLiteYoloXConfig, optional)¶
The megadetector_lite_config is used to specify any parameters that should be passed to the MegadetectorLite model for frame selection. For all possible options, see the MegadetectorLiteYoloXConfig class. If megadetector_lite_config is None (the default), the MegadetectorLite model will not be used to select frames.
frame_selection_height (int, optional), frame_selection_width (int, optional)¶
Resize the video to this height and width in pixels, prior to frame selection. If None, the full size video will be used for frame selection. Using full size videos (setting to None) is recommended for MegadetectorLite, especially if your species of interest are smaller. Defaults to None
total_frames (int, optional)¶
Number of frames that should ultimately be returned. Defaults to None
ensure_total_frames (bool)¶
Selecting the number of frames by resampling may result in one more or fewer frames due to rounding. If True, ensure the requested number of frames is returned by either clipping or duplicating the final frame. Raises an error if no frames have been selected. Otherwise, return the array unchanged. Defaults to True
fps (int, optional)¶
Resample the video evenly from the entire duration to a specific number of frames per second. Defaults to None
early_bias (bool, optional)¶
Resamples to 24 fps and selects 16 frames biased toward the front. This strategy was used by the Pri-matrix Factorization machine learning
competition winner. Defaults to False
frame_indices (list(int), optional)¶
Select specific frame numbers. Note: frame selection is done after any resampling. Defaults to None
evenly_sample_total_frames (bool, optional)¶
Reach the total number of frames specified by evenly sampling from the duration of the video. Defaults to False
pix_fmt (str, optional)¶
FFmpeg pixel format, defaults to rgb24 for RGB channels; can be changed to bgr24 for BGR.
model_input_height (int, optional), model_input_width (int, optional)¶
After frame selection, resize the video to this height and width in pixels. Defaults to None
cache_dir (Path, optional)¶
Cache directory where preprocessed videos will be saved upon first load. Alternatively, can be set with VIDEO_CACHE_DIR environment variable. Provided there is enough space on your machine, it is highly encouraged to cache videos for training as this will speed up all subsequent epochs. If you are predicting on the same videos with the same video loader configuration, this will save time on future runs. Defaults to None, which means videos will not be cached.
cleanup_cache (bool, optional)¶
Whether to delete the cache directory after training or predicting ends. Defaults to False
Prediction arguments¶
All possible model inference parameters are defined by the PredictConfig class. Let's see the class documentation in Python:
>> from zamba.models.config import PredictConfig
>> help(PredictConfig)
class PredictConfig(ZambaBaseModel)
| PredictConfig(*,
data_directory: DirectoryPath = # your current working directory ,
filepaths: FilePath = None,
checkpoint: FilePath = None,
model_name: zamba.models.config.ModelEnum = <ModelEnum.time_distributed: 'time_distributed'>,
gpus: int = 0,
num_workers: int = 3,
batch_size: int = 2,
save: Union[bool, pathlib.Path] = True,
dry_run: bool = False,
proba_threshold: float = None,
output_class_names: bool = False,
weight_download_region: zamba.models.utils.RegionEnum = 'us',
skip_load_validation: bool = False,
model_cache_dir: pathlib.Path = None) -> None
...
Either data_directory or filepaths must be specified to instantiate PredictConfig. Otherwise the current working directory will be used as the default data_directory.
data_directory (DirectoryPath, optional)¶
Path to the directory containing training videos. Defaults to the current working directory.
filepaths (FilePath, optional)¶
Path to a list of files for classification. Defaults to the files in the current working directory
checkpoint (Path or str, optional)¶
Path to a model checkpoint to load and use for inference. The default is None, which automatically loads the pretrained checkpoint for the model specified by model_name. Since the default model_name is time_distributed the default checkpoint is zamba_time_distributed.ckpt
model_name (time_distributed|slowfast|european, optional)¶
Name of the model to use for inference. The three model options that ship with zamba are time_distributed, slowfast, and european. See the Available Models page for details. Defaults to time_distributed
gpus (int, optional)¶
The number of GPUs to use during inference. By default, all of the available GPUs found on the machine will be used. An error will be raised if the number of GPUs specified is more than the number that are available on the machine.
num_workers (int, optional)¶
The number of CPUs to use during training. The maximum value for num_workers is the number of CPUs available on the machine. If you are using MegadetectorLite for frame selection, it is not recommended to use the total number of CPUs available. Defaults to 3
batch_size (int, optional)¶
The batch size to use for inference. Defaults to 2
save (bool, optional)¶
Whether to save out the predictions to a CSV file. y default, predictions will be saved at zamba_predictions.csv in the current working directory. Defaults to True
dry_run (bool, optional)¶
Specifying True is useful for trying out model implementations more quickly by running only a single batch of inference. Defaults to False
proba_threshold (float between 0 and 1, optional)¶
For advanced uses, you may want the algorithm to be more or less sensitive to if a species is present. This parameter is a FLOAT number, e.g., 0.64 corresponding to the probability threshold beyond which an animal is considered to be present in the video being analyzed.
By default no threshold is passed, proba_threshold=None. This will return a probability from 0-1 for each species that could occur in each video. If a threshold is passed, then the final prediction value returned for each class is probability >= proba_threshold, so that all class values become 0 (False, the species does not appear) or 1 (True, the species does appear).
output_class_names (bool, optional)¶
Setting this option to True yields the most concise output zamba is capable of. The highest species probability in a video is taken to be the only species in that video, and the output returned is simply the video name and the name of the species with the highest class probability, or blank if the most likely classification is no animal. Defaults to False
weight_download_region [us|eu|asia]¶
Because zamba needs to download pretrained weights for the neural network architecture, we make these weights available in different regions. us is the default, but if you are not in the US you should use either eu for the European Union or asia for Asia Pacific to make sure that these download as quickly as possible for you.
skip_load_validation (bool, optional)¶
By default, before kicking off inference zamba will iterate through all of the videos in the data and verify that each can be loaded. Setting skip_load_verification to True skips this step. Validation can be very time intensive depending on the number of videos. It is recommended to run validation once, but not on future inference runs if the videos have not changed. Defaults to False
model_cache_dir (Path, optional)¶
Cache directory where downloaded model weights will be saved. If None and the MODEL_CACHE_DIR environment variable is not set, will use your default cache directory (e.g. ~/.cache). Defaults to None
Training arguments¶
All possible model training parameters are defined by the TrainConfig class. Let's see the class documentation in Python:
>> from zamba.models.config import TrainConfig
>> help(TrainConfig)
class TrainConfig(ZambaBaseModel)
| TrainConfig(*,
labels: Union[FilePath, pandas.DataFrame],
data_directory: DirectoryPath = # your current working directory ,
checkpoint: FilePath = None,
scheduler_config: Union[str, zamba.models.config.SchedulerConfig, NoneType] = 'default',
model_name: zamba.models.config.ModelEnum = <ModelEnum.time_distributed: 'time_distributed'>,
dry_run: Union[bool, int] = False,
batch_size: int = 2,
auto_lr_find: bool = True,
backbone_finetune_config: zamba.models.config.BackboneFinetuneConfig =
BackboneFinetuneConfig(unfreeze_backbone_at_epoch=15,
backbone_initial_ratio_lr=0.01, multiplier=1,
pre_train_bn=False, train_bn=False, verbose=True),
gpus: int = 0,
num_workers: int = 3,
max_epochs: int = None,
early_stopping_config: zamba.models.config.EarlyStoppingConfig =
EarlyStoppingConfig(monitor='val_macro_f1', patience=3,
verbose=True, mode='max'),
weight_download_region: zamba.models.utils.RegionEnum = 'us',
split_proportions: Dict[str, int] = {'train': 3, 'val': 1, 'holdout': 1},
save_directory: pathlib.Path = # your current working directory ,
overwrite_save_directory: bool = False,
skip_load_validation: bool = False,
from_scratch: bool = False,
predict_all_zamba_species: bool = True,
model_cache_dir: pathlib.Path = None) -> None
...
data_directory and labels must be specified to instantiate TrainConfig. If no data_directory is provided, it will default the current working directory.
labels (FilePath or pd.DataFrame, required)¶
Either the path to a CSV file with labels for training, or a dataframe of the training labels. There must be columns for filename and label.
data_directory (DirectoryPath, optional)¶
Path to the directory containing training videos. Defaults to the current working directory.
checkpoint (Path or str, optional)¶
Path to a model checkpoint to load and resume training from. The default is None, which automatically loads the pretrained checkpoint for the model specified by model_name. Since the default model_name is time_distributed the default checkpoint is zamba_time_distributed.ckpt
scheduler_config (zamba.models.config.SchedulerConfig, optional)¶
A PyTorch learning rate schedule to adjust the learning rate based on the number of epochs. Scheduler can either be default (the default), None, or a torch.optim.lr_scheduler. If default,
model_name (time_distributed|slowfast|european, optional)¶
Name of the model to use for inference. The three model options that ship with zamba are time_distributed, slowfast, and european. See the Available Models page for details. Defaults to time_distributed
dry_run (bool, optional)¶
Specifying True is useful for trying out model implementations more quickly by running only a single batch of train and validation. Defaults to False
batch_size (int, optional)¶
The batch size to use for training. Defaults to 2
auto_lr_find (bool, optional)¶
Whether to run a learning rate finder algorithm when calling pytorch_lightning.trainer.tune() to find the optimal initial learning rate. See the PyTorch Lightning docs for more details. Defaults to True
backbone_finetune_config (zamba.models.config.BackboneFinetuneConfig, optional)¶
Set parameters to finetune a backbone model to align with the current learning rate. Derived from Pytorch Lightning's built-in BackboneFinetuning. The default values are specified in the BackboneFinetuneConfig class: BackboneFinetuneConfig(unfreeze_backbone_at_epoch=15, backbone_initial_ratio_lr=0.01, multiplier=1, pre_train_bn=False, train_bn=False, verbose=True)
gpus (int, optional)¶
The number of GPUs to use during training. By default, all of the available GPUs found on the machine will be used. An error will be raised if the number of GPUs specified is more than the number that are available on the machine.
num_workers (int, optional)¶
The number of CPUs to use during training. The maximum value for num_workers is the number of CPUs available in the system. If you are using the Megadetector, it is not recommended to use the total number of CPUs available. Defaults to 3
max_epochs (int, optional)¶
The maximum number of epochs to run during training. Defaults to None
early_stopping_config (zamba.models.config.EarlyStoppingConfig, optional)¶
Parameters to pass to Pytorch lightning's EarlyStopping to monitor a metric during model training and stop training when the metric stops improving. The default values are specified in the EarlyStoppingConfig class: EarlyStoppingConfig(monitor='val_macro_f1', patience=3, verbose=True, mode='max')
weight_download_region [us|eu|asia]¶
Because zamba needs to download pretrained weights for the neural network architecture, we make these weights available in different regions. us is the default, but if you are not in the US you should use either eu for the European Union or asia for Asia Pacific to make sure that these download as quickly as possible for you.
split_proportions (dict(str, int), optional)¶
The proportion of data to use during training, validation, and as a holdout set. Defaults to {"train": 3, "val": 1, "holdout": 1}
save_directory (Path, optional)¶
Directory in which to save model checkpoint and configuration file. If not specified, will save to a folder called 'zamba_{model_name}' in your working directory.
overwrite_save_directory (bool, optional)¶
If True, will save outputs in save_directory and overwrite the directory if it exists. If False, will create an auto-incremented version_n folder within save_directory with model outputs. Defaults to False.
skip_load_validation (bool, optional)¶
By default, before kicking off training zamba will iterate through all of the videos in the training data and verify that each can be loaded. Setting skip_load_verification to True skips this step. Validation can be very time intensive depending on the number of videos. It is recommended to run validation once, but not on future training runs if the videos have not changed. Defaults to False
from_scratch (bool, optional)¶
Whether to instantiate the model with base weights. This means starting from the imagenet weights for image based models and the Kinetics weights for video models. Only used if labels is not None. Defaults to False
predict_all_zamba_species (bool, optional)¶
Whether the species outputted by the model should be all zamba species. If you want the model classes to only be the species in your labels file, set to False. Only used if labels is not None. If either predict_all_zamba_species is False or the labels contain species that are not in the model, the model head will be replaced. Defaults to True.
model_cache_dir (Path, optional)¶
Cache directory where downloaded model weights will be saved. If None and the MODEL_CACHE_DIR environment variable is not set, will use your default cache directory, which is often an automatic temp directory at ~/.cache/zamba. Defaults to None.